동작 순서
[1단계]
사용자에게 전달 받은 URL과 머신러닝모델에서 필요한 특징값 35개를 추출합니다.특징값은 예측 결과가 특징값별 가중치, 악성 URL이 갖는 특징에 대한 논문을 참고하여 35개를 선정했으며 그 종류는 다음과 같습니다.
| 종류 | 특징값 목록 |
|---|---|
| 개수 기반 | 도메인 개수, http 개수, https 개수, . 개수, // 개수, - 개수, @ 개수, www 개수, = 개수, 개수, ~ 개수, ? 개수, &#% 개수, 악성 문자열 개수, 숫자 개수, 쿼리 개수, 쿼리 악성 문자열 개수, url_path 깊이 |
| 길이 기반 | url 길이, url path 길이, url netloc 길이, url tld 길이, 쿼리 길이 |
| 유무 기반 | 쿼리 인코딩 유무, url 내 ip 포함 여부, 단축 서비스 유무 |
| 비율 기반 | 랜덤한 정도, 대문자 알파벳 비율 |
| 도메인 기반 | 포트 번호, 도메인 생성일~현재, 현재~도메인 만료일, 도메인 전체 수명, 트래픽 길이, abnormal 유무 |
[2단계]
입력받은 특징값과 URL을 다음 8개의 모델에 입력하며 모델은 최신화가 지속적으로 진행| 모델 | 설명 |
|---|---|
| Random Forest Model | 다수의 결정 트리를 투표 방식으로 조합하여 입력된 URL이 악성인지 정상인지 판단하는 모델 |
| Gradient Boosting Model | 여러 약한 모델을 결합하여 이전 모델의 오차를 보완하면서 URL의 악성 여부를 판단하는데 사용 |
| Hist Gradient Boosting Model | 효율적인 히스토그램 기반 학습과 예측을 통해 URL의 악성 여부를 판단하며, 빠르고 정확한 결과를 제공 |
| Ensemble Model1(RF-GB-ET-MLP-LR) | 다양한 모델의 강점을 활용하여 URL의 악성 여부에 대한 정확한 분류 성능을 제공 |
| Ensemble Model1(DT-RF-KNN-MLP-LR) | K-최근접 이웃 모델을 포함한 다양한 알고리즘을 활용하여 URL의 악성 여부에 대한 높은 분류 정확도와 강건성을 제공 |
| Ensemble Model1(RF-GB-MLP-AB-HGB) | 에이다부스트 모델을 포함한 다양한 머신 러닝 기법을 활용하여 URL의 악성 여부를 판단 |
| Ensemble Model1(KNN-GNB-MLP-RF-GB) | URL의 악성 여부를 다양한 관점에서 평가하며, 다중 모델의 다양성을 통해 악성 URL에 대한 정확한 분류를 강화 |
| Convolutional Neural Network | 딥러닝 모델로 DGA에 대한 학습 결과를 바탕으로 해당 URL의 도메인이 DGA에 의한 생성 여부에 대해 예측값과 예측 확률을 출력 |
[3단계]
다음 8개의 모델을 성능별로 가중치를 부여하는 가중 다수결 조합방식으로 종합하여 특정 URl이 악성인지 아닌지 여부를 최종 출력URL
기존의 악성 url과는 다른 새로운 유형의 악성 url에 의한 피해를 방지하기 위한 방법을 고민해보았고
최신 악성 url들이 공통적으로 갖는 유의미한 특징값들을 추출하여 머신러닝 모델에서 학습하는 분류모델을 파이썬(Python) 환경에서 만들었다.
기존의 머신러닝을 활용한 악성 URL탐지 모델에서는 대부분 개수기반, 길이 기반, 존재 기반, 비율 기반 등의 어휘적 특징이 많이 사용되었다.
그러나 프로젝트 진행과정에서 어휘적 특징만을 활용한 악성 url탐지에는 한계가 있음을 확인하여
도메인 수명, 트래픽 길이, 도메인 생성일자와 같은 도메인 정보를 학습에 동시에 활용했다.
특징값의 추출 과정 역시 파이썬에서 이루어졌으며 도메인 정보와 같은 정보는 urllib라이브러리를 활용하여
추출했으며 출력된 특징값을 데이터화 하여 저장하기 위한 csv라이브러리, 학습이 가능한 형태로 저장하고 활용하기
위한 pandas라이브러리도 활용되었으며 모델 학습을 위한 sklearn라이브러리도 활용했다.
모델은 총 10개의 단일 모델을 활용했으며
각 모델은 joblib라이브러리를 활용해 .h5확장자 파일로 저장하여 활용했다.
학습에 활용되지 않은 데이터를 활용한 성능테스트 결과
RF(RandomForest), GB(GradientBoosting), HGB(HistGradientBoosting)의 3가지 모델이 단일모델로는 가장 높은 성능을 보였으며
조합 모델은 대체적으로 높은 성능을 보였으나 스태킹방식으로는 RF-GB-ET-MLP-LR, DT-RF-KN-MLP-LR, RF-GB-MLP-AB-HGB가,
보팅 방식으로는 RF-GB-HGB가 가장 높은 성능을 보여 다음 7개의 모델을 최종 선택하게 되었다.
모델의 구동 방식은 다음과 같이 입력받은 데이터를 전처리(Vectorization)하여
7개의 모델에 입력하고 그 결과값들을 가중 다수결 조합 방식에 따라 계산하여 최종 결과를 출력하는 형태로 진행되었다.
DGA
DGA를 탐지하는 CNN모델을 구현하였으며 모델과 전처리, 임베딩 과정은 "남궁주홍. DGA 도메인 탐지를 위한 효율적인 딥러닝 모델." 국내석사학위논문 강원대학교 대학원, 2020.강원도 논문을 기준으로 구성하였다. 논문에서는 패딩 사이즈를 73, 출력 차원을 32로 설정하였고 오버 피팅을 막기 위해 dropout(0.5)과 regularization을 적용하였는데 사용한 데이터셋에서 가장 긴 url의 데이터 길이가 64이기 때문에 패딩 사이즈를 64로 제로 패딩하였고 차원은 똑같이 32, dropout은 0.5, L2 regularization 0.15로 진행하였다.
데이터셋 : https://www.kaggle.com/datasets/gtkcyber/dga-dataset CNN 모델의 구성은 커널의 입력 길이를 2-5까지 각각 다르게 하는 4개의 1D Convolutional layer를 하나의 Concatenate layer로 합친 후 3개의 Hidden layer를 거치고 출력된다. Hidden 레이어의 구성은 Fully-connected 후 activation function인 ELU를 사용하며 Batch Normalization(배치 정규화)후 0.5의 가중치를 준 dropout이다. 논문에서 그린 모델의 아키텍쳐는 다음과 같다.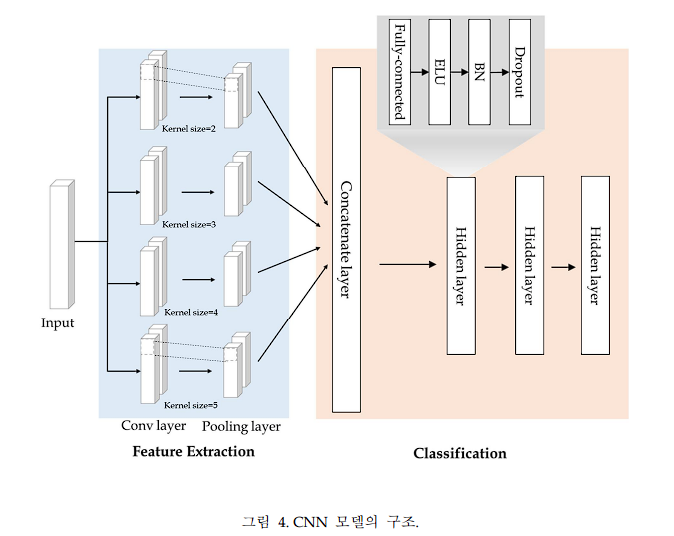
| DGA | 설명 |
|---|---|
| CryptoLocker | DGA를 사용하여 C&C 서버에 연결하고, 암호화된 파일을 복원하기 위해 피해자에게 요구하는 도메인을 동적으로 생성 |
| NewGoz | 금융 부문을 타겟으로 하는 악성 코드로, DGA를 사용하여 악성 서버와 통신하고 금전적 이익을 추출하는 데 활용 |
| GameOverDGA | DGA를 사용하여 봇넷과 통신하며, 금융 정보를 탈취하고 악성 활동을 숨기기 위해 동적 도메인을 생성 |
| Nivdort | DGA를 활용하여 트로이목마를 배포하고, 사용자의 개인 정보를 탈취하거나 다른 악성 코드를 설치 |
| Necurs | 대규모 스팸 및 악성 파일 배포를 위해 DGA를 사용하며, 다양한 악성 활동에 이용 |
| Goz | 금융 정보를 탈취하고 악성 활동을 숨기기 위해 DGA를 활용하는 악성 코드 |
| Bamital | 클릭 사기 및 광고 클릭 부정행위를 실행하며 DGA를 사용하여 도메인을 동적으로 생성하여 악성 활동을 수행 |
